
Previous work on evaluating heterogeneous treatment effect (HTE) model selection metrics has focused on the Precision of Estimating Heterogeneous Effects (PEHE) which treats each observation equally. But in some use-cases for HTE models we may not care equally about everyone. For user-level targeting based on the HTE predictions, we care more about the set of users who are near the decision boundary for the targeting as opposed to those who will almost always be/not be targeted. We propose new HTE model selection metrics that weigh users differently and compare how they perform on both simulated and real data. Our results suggest an improved model selection metric based on Off-Policy Evaluation (OPE) when the goal is to target a subset of the population. Our results extend the literature on HTE model selection by providing an easy-to-compute metric that performs well for a subset of common HTE models.
Most user-level targeting takes the form of ranking users by predicted treatment effect and targeting the top X%. OPE provides a tool to evaluate a given ranking on historical data, which means we can use it to compare rankings from two different models. We propose using OPE as a model selection metric for certain HTE problems. We compare this new metric with some of the existing methodologies (AUUC, R-Loss, Transformed Outcomes) as well as a new weighted R-Loss metric that attempts to weigh influential users more. We compare using industry-standard synthetic datasets as well as using real Lyft data. We show that the existing metrics do a good job of recovering PEHE, but our OPE metric does better at model selection for targeting use-cases.
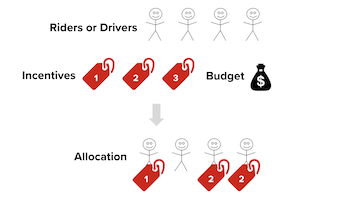
The Incentives Platform team at Lyft has developed a platform for applying new methodologies at the intersection of causal inference, machine learning, and reinforcement learning to problems at scale. We utilize heterogeneous treatment effect algorithms to predict how different users (riders, drivers) will respond to a specific treatment (coupon, incentive, message, etc.). We then can apply various optimization algorithms to choose which users get which treatment while using bandit methodologies to balance an explore/exploit trade-off. This platform dramatically increases the degree to which we can customize the user experience and hit business goals while reducing the operational load of doing so.
This platform lets us understand how our users differ; letting us optimally target users based on individual treatment effect predictions; and evaluate the results of these predictions. The platform is built in a flexible way to allow us to plug-and-play with different algorithms, which lets us compare performance and develop improvements. We have integrated Off-Policy Evaluation into the platform allowing us to make unbiased (backtesting) evaluations of causal effects, without needing to run an AB test.
While the scale of our data and complexity of these algorithms requires substantial engineering infrastructure, we have built the platform in a modular way that allows for separation between the science and engineering code. This makes it easy for data scientists to iterate on these models without worrying (as much) about infrastructure or distributed systems.
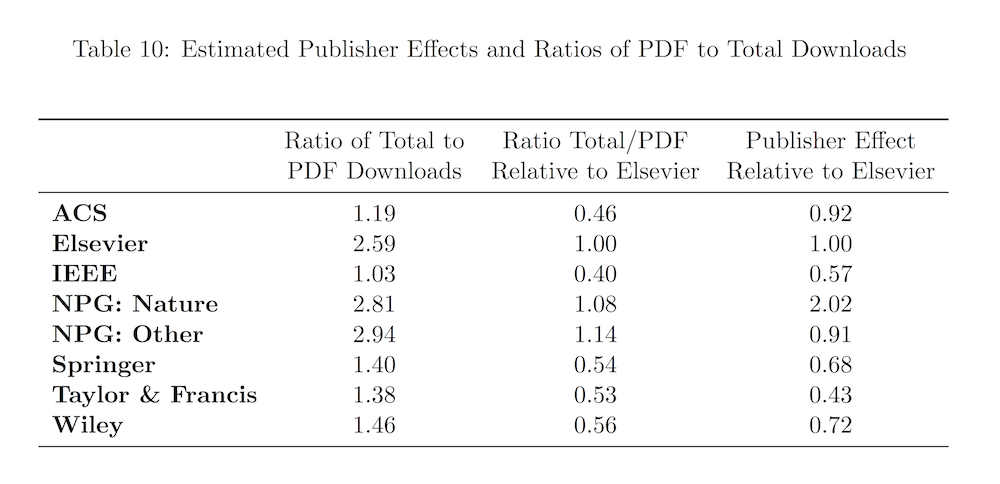
Download rates of academic journals have joined citation counts as commonly used indicators of the value of journal subscriptions. While citations reflect worldwide influence, the value of a journal subscription to a single library is more reliably measured by the rate at which it is downloaded by local users. If reported download rates accurately measure local usage, there is a strong case for using them to compare the cost-effectiveness of journal subscriptions. We examine data for nearly 8,000 journals downloaded at the ten universities in the University of California system during a period of six years. We find that controlling for number of articles, publisher, and year of download, the ratio of downloads to citations differs substantially among academic disciplines. After adding academic disciplines to the control variables, there remain substantial “publisher effects”, with some publishers reporting significantly more downloads than would be predicted by the characteristics of their journals. These cross-publisher differences suggest that the currently available download statistics, which are supplied by publishers, are not sufficiently reliable to allow libraries to make subscription decisions based on price and reported downloads, at least without making an adjustment for publisher effects in download reports.
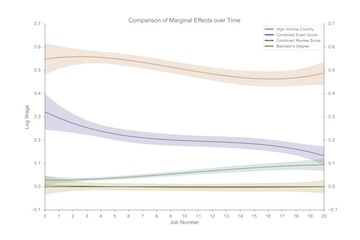
Much of the new “gig economy” relies on reputation systems to reduce problems of asymmetric information. There is evidence that one aspect of these reputation systems, online reviews, provide information to these markets. However, less is known about how these reviews interact and compare with other pieces of information in these markets. This paper provides a more complete picture of the reputation system in an online labor market. I compare the informational content of online reviews with other sources of information about worker ability, including the review comments, standardized exam scores, and the worker’s country. I estimate the effect of each component on wages and worker attrition. Reviews have a relatively small effect on both wages and attrition, however, I am able to separate out the dual role of reviews: rewarding good workers and punishing bad ones. Finally, I investigate why firms leave reviews at all, and find that firm reputation and re-hiring considerations incentivize firms to leave informative reviews.
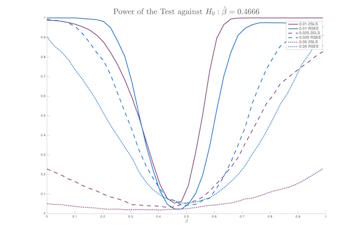
The ability to estimate peer effects in network models has been advanced considerably by the IV model of Bramoullé et al. (2009). While such IV estimates work well for very sparse networks, they exhibit very weak power for networks of even modest densities. We review and extend the findings of Bramoullé et al. (2009) and then propose an alternative estimator. We show that our new estimator works approximately as well as IV in very sparse networks and performs much better in networks of moderate density.